Overview
Enterprise search remains a significant challenge within organizations, with teams reportedly wasting up to 32 days a year navigating through multiple tools to find answers.
At Askollo, we address this problem by building a robust enterprise search engine that seamlessly integrates with the tools teams already use – such as Notion, Google Drive, and Slack – via simple pre-built integrations and APIs.
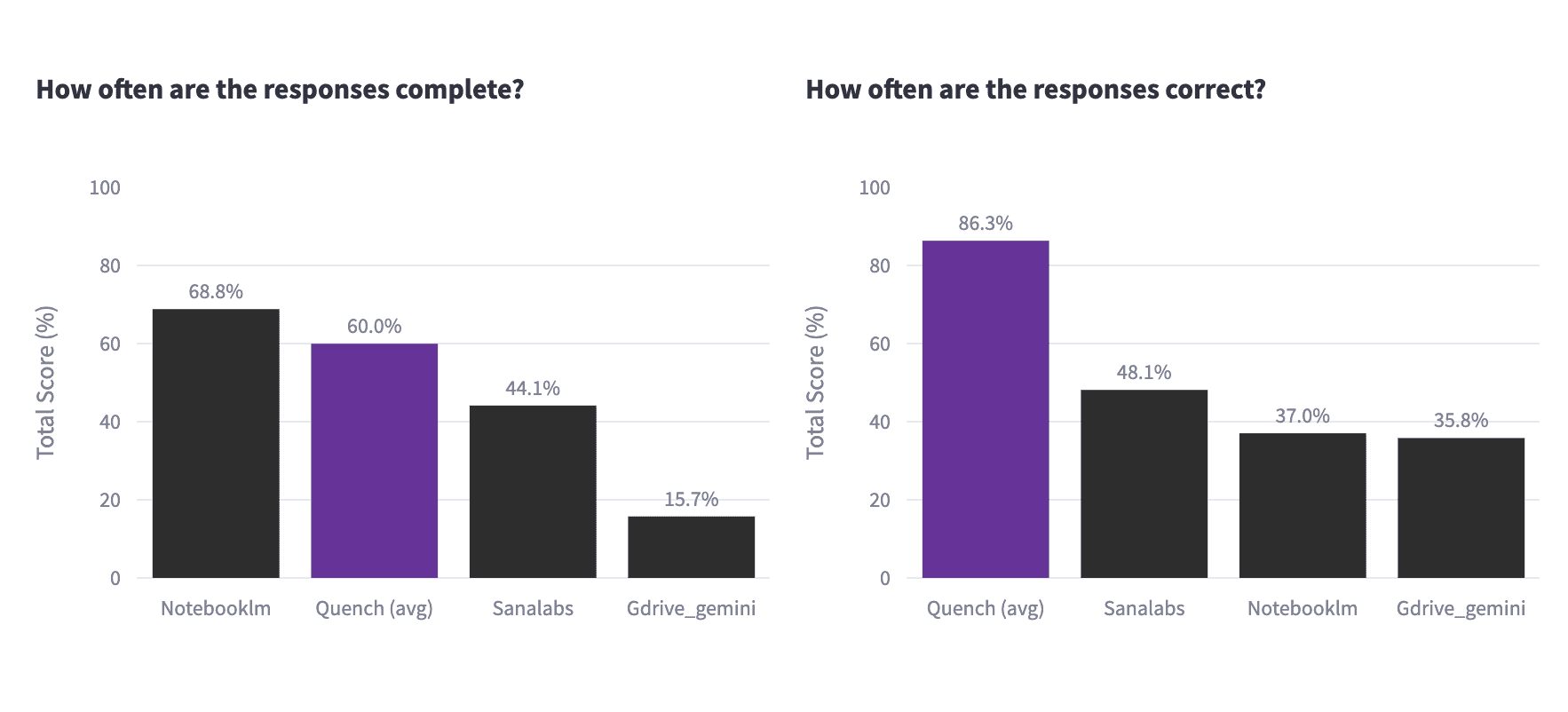
In our work with businesses, we've learned that delivering correct answers is paramount. Enterprises are understandably wary of inaccuracies or hallucinations from Retrieval-Augmented Generation (RAG) solutions.
With this in mind, we conducted a comprehensive analysis of enterprise search tools, comparing Askollo against Sana Labs, NotebookLM, and Google Drive Gemini by running over 300 ollomark our precision against your internal solution, we are up for the challenge.
You can sign up here and a member of our team will be happy to help you get started.
Our Method
- Choosing Sample Datasets and Creating User Personas:
We selected two companies to test our system and created a user persona for them - employees seeking quick and accurate answers about company processes and product information.
- Generating Questions:
We configured a LLM to create questions based on each dataset's content, while fitting the persona. For each question, we would also ask the LLM to state the asset from which the question was inspired from.
- Crafting Reference Answers:
We used multiple LLM agents to scour the asset for claims that are relevant for the question. We then configured LLMs to leverage this information and craft a detailed and well supported answer.
- Retrieving Answers from Enterprise Search Tools:
We obtained results from Askollo as well as the following knowledge management RAG tools, which all have the same datasets uploaded to it:- Sana Labs
- NotebookLM
- Google Drive Gemini
- Comparing Answers:
We used a LLM judge to simulate human labelling. We set the labelling task in accordance with best practices learned from managing human labelling:- The task needs to be binary. When comparing 2 answers, the only possible verdicts are the following:
- Answer 1 > Answer 2
- Answer 1 < Answer 2
- Both are equally good
- Both are equally poor
- All the context required to correctly label the predictions needs to be included in the task. Do not rely on labellers’ memory / pre-trained knowledge if possible.
- Alongside this, we provided the list of reference claims and relevant citations for the LLM to make its decision. We asked the LLM to generate a verdict based on both completeness and correctness. We used GPT-4o to be the judge as it better aligns with human preferences.
- The task needs to be binary. When comparing 2 answers, the only possible verdicts are the following:
Current Limitations of Our Study
- Challenges in Assigning Correctness Scores – Our current approach flags responses as "complete but incorrect," but lacks a fine-grained way to measure partial correctness (e.g., a score of 0.5 instead of 0).
- Reliance on Generated Reference Answers: Our current approach leverages multiple LLMs to generate reference answers to questions. While we’ve engineered this to best align with human preferences, it is more ideal for reference answers to come from human experts.
- Reliance on Automated Evaluations: Our method uses GPT-4o as a judge to simulate human preference labelling. While this method showed good alignment with human preferences, we didn’t measure its alignment with human SME preferences. Further validation against human SMEs in specialised fields could ensure robustness of our approach.